You're reading for free via Gary A. Stafford's Friend Link. Become a member to access the best of Medium.
Member-only story
Utilizing In-memory Data Caching to Enhance the Performance of Data Lake-based Applications on AWS
Significantly improve the performance and reduce the cost of data lake-based analytics applications using Amazon ElastiCache for Redis
Introduction
The recent post, Developing Spring Boot Applications for Querying Data Lakes on AWS using Amazon Athena, demonstrated how to develop a Cloud-native analytics application using Spring Boot. The application queried data in an Amazon S3-based data lake via an AWS Glue Data Catalog utilizing the Amazon Athena API.
Securely exposing data in a data lake using RESTful APIs can fulfill many data-consumer needs. However, access to that data can be significantly slower than access from a database or data warehouse. For example, in the previous post, we imported the OpenAPI v3 specification from the Spring Boot service into Postman. The API specification contained approximately 17 endpoints.
From my local development laptop, the Postman API test run times for all service endpoints took an average of 32.4 seconds. The Spring Boot service was running three Kubernetes pod replicas on Amazon EKS in the AWS US East (N. Virginia) Region.
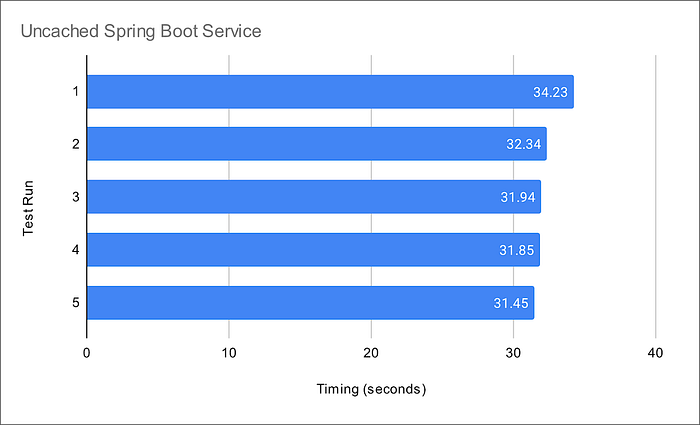
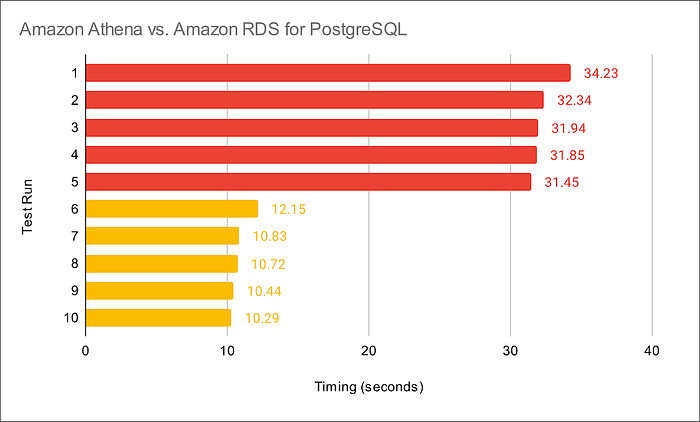
Compare the data lake query result times to equivalent queries made against a minimally-sized Amazon RDS for PostgreSQL database instance containing the same data. The average run times for all PostgreSQL queries averaged 10.8 seconds from a similar Spring Boot service. Although not a precise benchmark, we can clearly see that access to the data in the Amazon S3-based data lake is substantially slower, approximately 3x slower, than that of the PostgreSQL database. Tuning the database would easily create an even greater disparity.
Caching for Data Lakes
According to AWS, the speed and throughput of a database can be the most impactful factor for overall application performance. Consequently, in-memory data caching can be one of the most effective strategies to improve overall application performance and reduce database costs. This same caching strategy can be applied to analytics applications built atop data lakes, as this post will demonstrate.

In-memory Caching
According to Hazelcast, memory caching (aka in-memory caching), often simply referred to as caching, is a technique in which computer applications temporarily store data in a computer’s main memory (e.g., RAM) to enable fast retrievals of that data. The RAM used for the temporary storage is known as the cache. As an application tries to read data, typically from a data storage system like a database, it checks to see if the desired record already exists in the cache. If it does, the application will read the data from the cache, thus eliminating the slower access to the database. If the desired record is not in the cache, then the application reads the record from the source. When it retrieves that data, it writes it to the cache so that when the application needs that same data in the future, it can quickly retrieve it from the cache.
Redis In-memory Data Store
According to their website, Redis is the open-source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. In addition, Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Amazon ElastiCache for Redis
According to AWS, Amazon ElastiCache for Redis, the fully-managed version of Redis, according to AWS, is a blazing fast in-memory data store that provides sub-millisecond latency to power internet-scale real-time applications. Redis applications can work seamlessly with ElastiCache for Redis without any code changes. ElastiCache for Redis combines the speed, simplicity, and versatility of open-source Redis with manageability, security, and scalability from AWS. As a result, Redis is an excellent choice for implementing a highly available in-memory cache to decrease data access latency, increase throughput, and ease the load on relational and NoSQL databases.
ElastiCache Performance Results
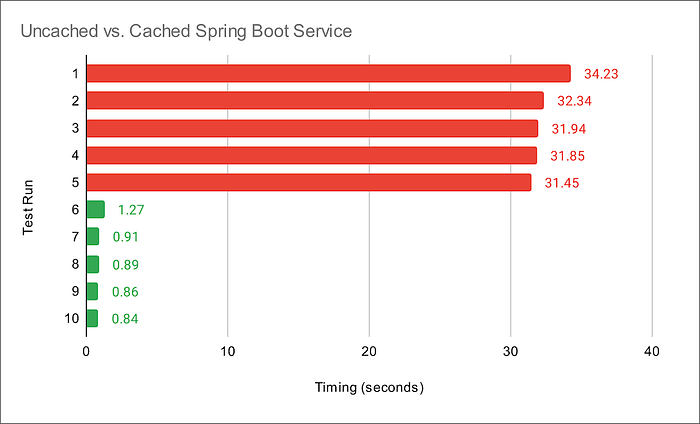
In the following post, we will add in-memory caching to the Spring Boot service introduced in the previous post. In preliminary tests with Amazon ElastiCache for Redis, the Spring Boot service delivered a 34x improvement in average response times. For example, test runs with the best-case-scenario of a Redis cache hit ratio of 100% averaged 0.95 seconds compared to 32.4 seconds without Redis.
Source Code
All the source code and Docker and Kubernetes resources are open-source and available on GitHub.
git clone --depth 1 -b redis \
https://github.com/garystafford/athena-spring-app.gitIn addition, a Docker image for the Redis-base Spring Boot service is available on Docker Hub. For this post, use the latest tag with the .redis suffix.
Code Changes
The following code changes are required to the Spring Boot service to implement Spring Boot Cache with Redis.
Gradle Build
The gradle.build file now implements two additional dependencies, Spring Boot’s spring-boot-starter-cache and spring-boot-starter-data-redis (lines 45–46).
Application Properties
The application properties file, application.yml, has been modified for both the dev and prod Spring Profiles. The dev Spring Profile expects Redis to be running on localhost. Correspondingly, the project’s docker-compose.yml file now includes a Redis container for local development. The time-to-live (TTL) for all Redis caches is arbitrarily set to one minute for dev and five minutes for prod. To increase application performance and reduce the cost of querying the data lake using Athena, increase Redis’s TTL. Note that increasing the TTL will reduce data freshness.
Athena Application Class
The AthenaApplication class declaration is now decorated with Spring Framework’s EnableCaching annotation (line 22). Additionally, two new Beans have been added (lines 58–68). Spring Redis provides an implementation for the Spring cache abstraction through the org.springframework.data.redis.cache package. The RedisCacheManager cache manager creates caches by default upon the first write. The RedisCacheConfiguration cache configuration helps to customize RedisCache behavior such as caching null values, cache key prefixes, and binary serialization.
POJO Data Model Classes
Spring Boot Redis caching uses Java serialization and deserialization. Therefore, all the POJO data model classes must implement Serializable (line 14).
Service Classes
Each public method in the Service classes is now decorated with Spring Framework’s Cachable annotation (lines 42 and 66). For example, the findById(int id) method in the CategoryServiceImp class is annotated with @Cacheable(value = "categories", key = "#id"). The method’s key parameter uses Spring Expression Language (SpEL) expression for computing the key dynamically. Default is null, meaning all method parameters are considered as a key unless a custom keyGenerator has been configured. If no value is found in the Redis cache for the computed key, the target method will be invoked, and the returned value will be stored in the associated cache.
Controller Classes
There are no changes required to the Controller classes.
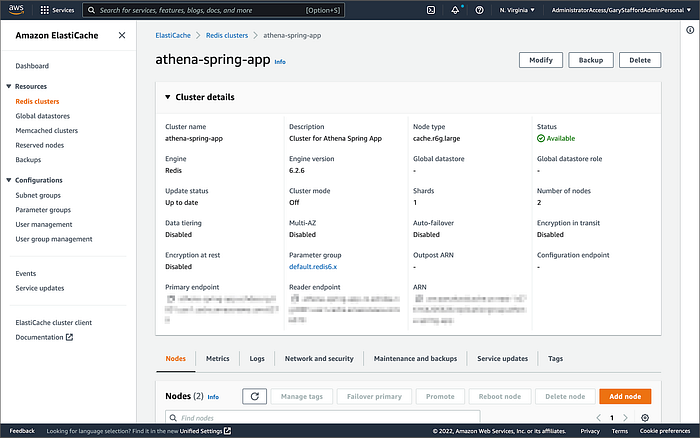
Amazon ElastiCache for Redis
Multiple options are available for creating an Amazon ElastiCache for Redis cluster, including cluster mode, multi-AZ option, auto-failover option, node type, number of replicas, number of shards, replicas per shard, Availability Zone placements, and encryption at rest and encryption in transit options. The results in this post are based on a minimally-configured Redis version 6.2.6 cluster, with one shard, two cache.r6g.large nodes, and cluster mode, multi-AZ option, and auto-failover all disabled. In addition, encryption at rest and encryption in transit were also disabled. This cluster configuration is sufficient for development and testing, but not Production.

Testing the Cache
To test Amazon ElastiCache for Redis, we will use Postman again with the imported OpenAPI v3 specification. With all data evicted from existing Redis caches, the first time the Postman tests run, they cause the service’s target methods to be invoked and the returned data stored in the associated caches.
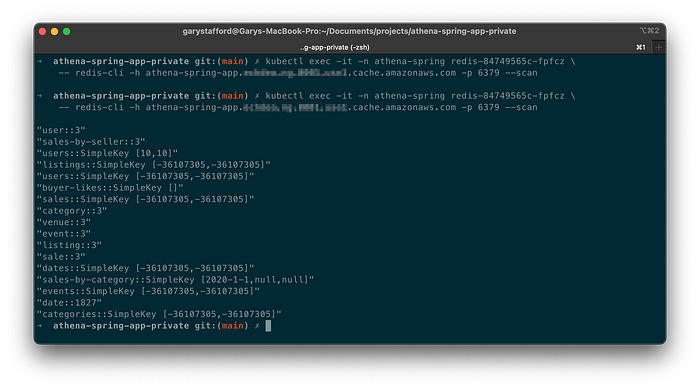
To confirm this caching behavior, use the Redis CLI’s --scan option. To access the redis-cli, I deployed a single Redis pod to Amazon EKS. The first time the --scan command runs, we should get back an empty list of keys. After the first Postman test run, the same --scan command should return a list of cached keys.
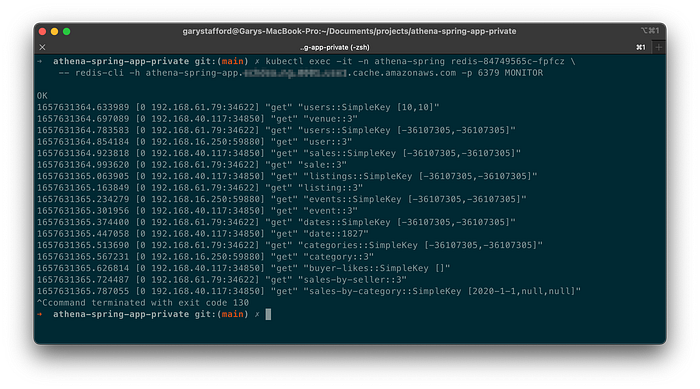
Use the Redis CLI’s MONITOR option to further confirm data is being cached, as indicated by the set command.
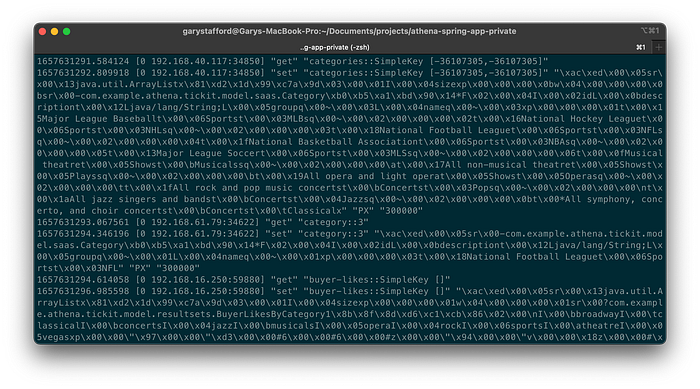
After the initial caching of data, use the Redis CLI’s MONITOR option, again, to confirm the cache is being hit instead of calling the target methods, which would then invoke the Athena API. Rerunning the Postman tests, we should see get commands as opposed to set commands.
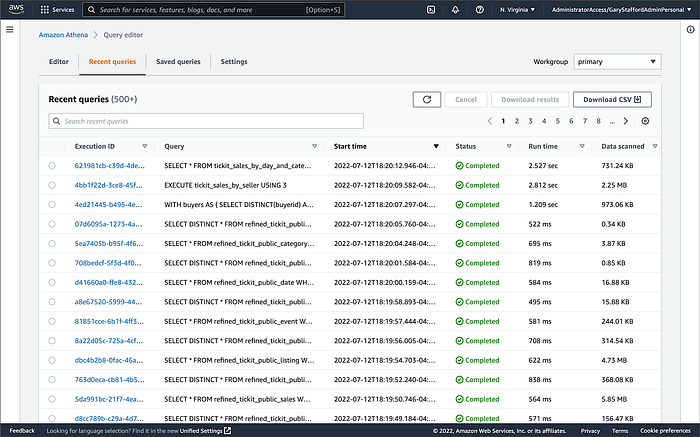
Lastly, to confirm the Spring Boot service is effectively using Redis to cache data, we can also check Amazon Athena’s Recent queries tab in the AWS Management Console. After repeated sequential test runs within the TTL window, we should only see one Athena query per endpoint.
Conclusion
In this brief follow-up to the recent post, Developing Spring Boot Applications for Querying Data Lakes on AWS using Amazon Athena, we saw how to substantially increase data lake application performance using Amazon ElastiCache for Redis. Although this caching technique is often associated with databases, it can also be effectively applied to data lake-based applications, as demonstrated in the post.
This blog represents my viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners. All diagrams and illustrations are property of the author unless otherwise noted.

