Member-only story
The Art of Building Open Data Lakes with Apache Hudi, Kafka, Hive, and Debezium
Build near real-time, open-source data lakes on AWS using a combination of Apache Kafka, Hudi, Spark, Hive, and Debezium
16 min readJan 1, 2022
Introduction
In the following post, we will learn how to build a data lake on AWS using a combination of open-source software (OSS), including Red Hat’s Debezium, Apache Kafka, Kafka Connect, Apache Hive, Apache Spark, Apache Hudi, and Hudi DeltaStreamer. We will use fully-managed AWS services to host the datasource, the data lake, and the open-source tools. These services include Amazon RDS, MKS, EKS, EMR, and S3.
This post is an in-depth follow-up to the video demonstration, Building Open Data Lakes on AWS with Debezium and Apache Hudi.
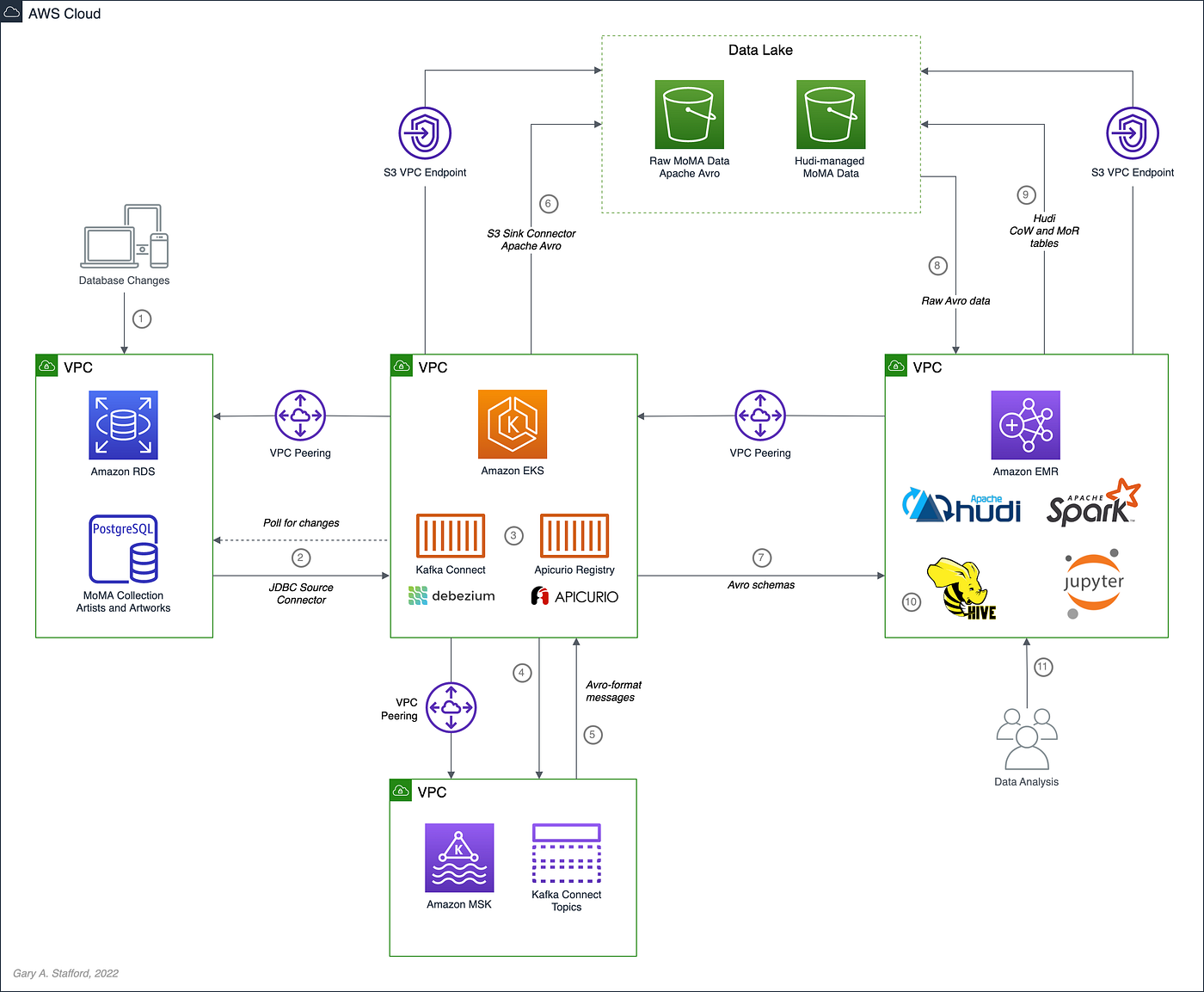
Workflow
As shown in the architectural diagram above, these are the high-level steps in the demonstration’s workflow:
- Changes (inserts, updates, and deletes) are made to the datasource, a PostgreSQL database running on Amazon RDS;
- Kafka Connect Source Connector, utilizing Debezium and running on Amazon EKS (Kubernetes), continuously reads data from PostgreSQL WAL using Debezium;
- Source Connector creates and stores message schemas in Apicurio Registry, also running on Amazon EKS, in Avro format;
- Source Connector transforms and writes data in Apache Avro format to Apache Kafka, running on Amazon MSK;
- Kafka Connect Sink Connector, using Confluent S3 Sink Connector, reads messages from Kafka topics using schemas from Apicurio Registry;
- Sink Connector writes data to Amazon S3 in Apache Avro format;
- Apache Spark, using Hudi DeltaStreamer and running on Amazon EMR, reads message schemas from Apicurio Registry;
- DeltaStreamer reads raw Avro-format data from Amazon S3;
