Member-only story
Stream Processing with Apache Spark, Kafka, Avro, and Apicurio Registry on AWS using Amazon MSK and EMR
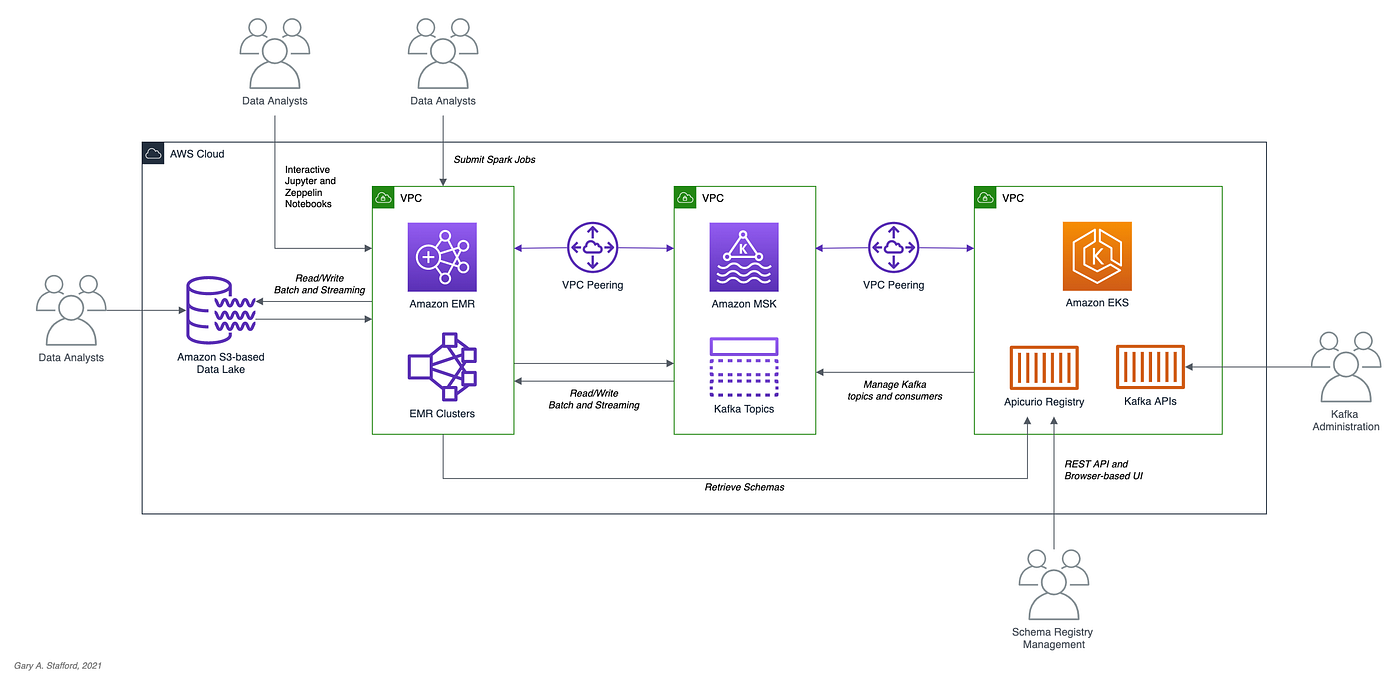
Using a registry to decouple schemas from messages in an event streaming analytics architecture
In the last post, Getting Started with Spark Structured Streaming and Kafka on AWS using Amazon MSK and Amazon EMR, we learned about Apache Spark and Spark Structured Streaming on Amazon EMR (fka Amazon Elastic MapReduce) with Amazon Managed Streaming for Apache Kafka (Amazon MSK). We consumed messages from and published messages to Kafka using both batch and streaming queries. In that post, we serialized and deserialized messages to and from JSON using schemas we defined as a StructType (pyspark.sql.types.StructType) in each PySpark script. Likewise, we constructed similar structs for CSV-format data files we read from and wrote to Amazon S3.
schema = StructType([
StructField("payment_id", IntegerType(), False),
StructField("customer_id", IntegerType(), False),
StructField("amount", FloatType(), False),
StructField("payment_date", TimestampType(), False),
StructField("city", StringType(), True),
StructField("district", StringType(), True),
StructField("country", StringType(), False),
])In this follow-up post, we will read and write messages to and from Amazon MSK in Apache Avro format. We will store the Avro-format Kafka message’s key and value schemas in Apicurio Registry and retrieve the schemas instead of hard-coding the schemas in the PySpark scripts. We will also use the registry to store schemas for CSV-format data files.
Video Demonstration
In addition to this post, there is now a video demonstration available on YouTube.
Technologies
In the last post, Getting Started with Spark Structured Streaming and Kafka on AWS using Amazon MSK and Amazon EMR, we learned about Apache Spark, Apache Kafka, Amazon EMR, and Amazon MSK.

