Member-only story
Getting Started with Spark Structured Streaming and Kafka on AWS using Amazon MSK and Amazon EMR
Exploring Apache Spark with Apache Kafka using both batch queries and Spark Structured Streaming
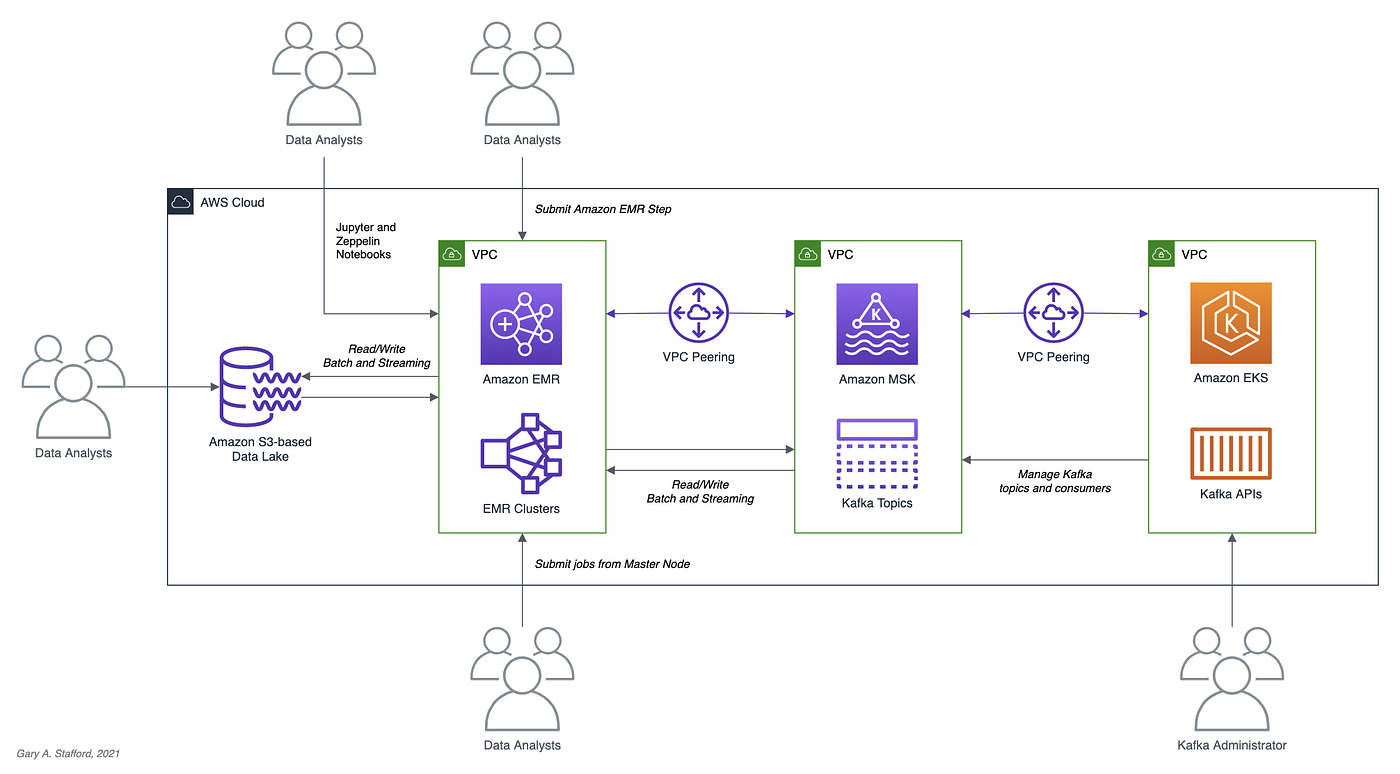
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. Using Structured Streaming, you can express your streaming computation the same way you would express a batch computation on static data. In this post, we will learn how to use Apache Spark and Spark Structured Streaming with Apache Kafka. Specifically, we will utilize Structured Streaming on Amazon EMR (fka Amazon Elastic MapReduce) with Amazon Managed Streaming for Apache Kafka (Amazon MSK). We will consume from and publish to Kafka using both batch and streaming queries. Spark jobs will be written in Python with PySpark for this post.
Apache Spark
According to the documentation, Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python (PySpark), and R, and an optimized engine that supports general execution graphs. In addition, Spark supports a rich set of higher-level tools, including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.

Spark Structured Streaming
According to the documentation, Spark Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will run it incrementally and continuously and update the final result as streaming data continues to arrive. In short, Structured Streaming provides fast, scalable, fault-tolerant, end-to-end, exactly-once stream processing without the user having to reason about streaming.

