Member-only story
Exploring Popular Open-source Stream Processing Technologies: Part 2 of 2
A brief demonstration of Apache Spark Structured Streaming, Apache Kafka Streams, Apache Flink, and Apache Pinot with Apache Superset
According to TechTarget, “Stream processing is a data management technique that involves ingesting a continuous data stream to quickly analyze, filter, transform or enhance the data in real-time. Once processed, the data is passed off to an application, data store, or another stream processing engine.” Confluent, a fully-managed Apache Kafka market leader, defines stream processing as “a software paradigm that ingests, processes, and manages continuous streams of data while they’re still in motion.”
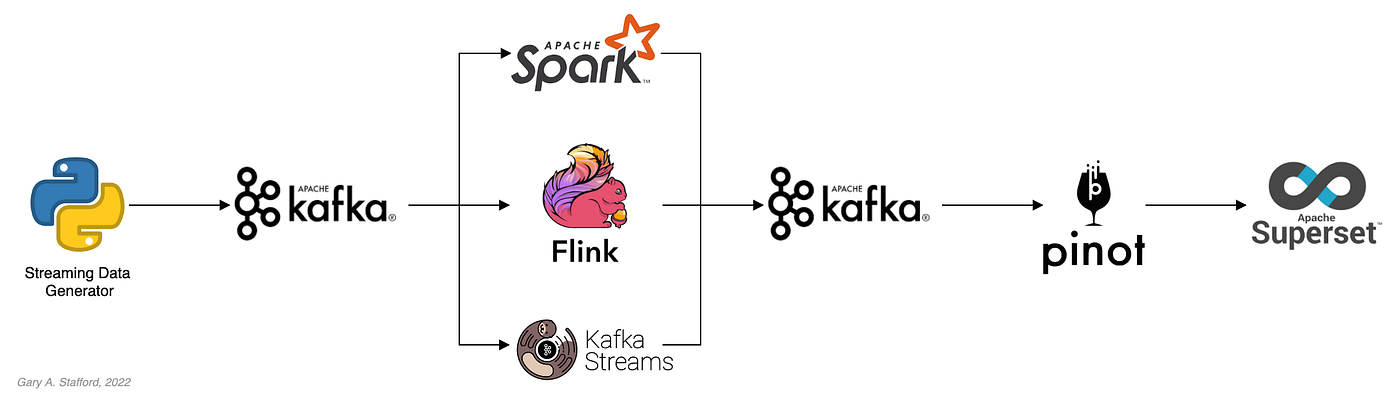
This two-part blog post and video demonstrations on YouTube explore four popular open-source software (OSS) stream processing projects: Apache Spark Structured Streaming, Apache Kafka Streams, Apache Flink, and Apache Pinot.
This post uses the open-source projects, making it easier to follow along with the demonstration and keeping costs to a minimum. However, you could easily substitute the open-source projects for your preferred SaaS, CSP, or COSS service offerings.
Part Two
We will continue our exploration from part one. In part two we will cover Apache Flink and Apache Pinot. In addition, we will incorporate Apache Superset into the demonstration to visualize the real-time results of our stream processing pipelines as a dashboard.
Demonstration #3: Apache Flink
In the third demonstration of four, we will examine Apache Flink. For this part of the post, we will also use the third of the three GitHub repository projects, flink-kafka-demo. The project contains a Flink application written in Java, which performs stream processing, incremental aggregation, and multi-stream joins.
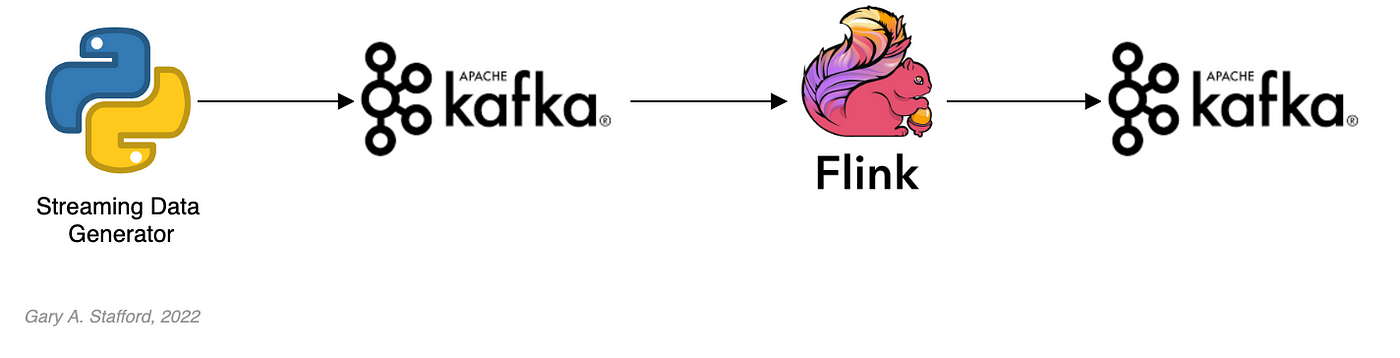
New Streaming Stack
To get started, we need to replace the first streaming Docker Swarm stack, deployed…

