Member-only story
Building a Data Lake on AWS
Build a simple Data Lake on AWS using a combination of services, including AWS Glue, AWS Glue Studio, Amazon Athena, and Amazon S3
Introduction
In the following video demonstration, we will build a simple data lake on AWS using a combination of services, including AWS Glue Data Catalog, AWS Glue Crawlers, AWS Glue Jobs, AWS Glue Studio, Amazon Athena, Amazon Relational Database Service (Amazon RDS), and Amazon S3.
We will catalog and move data from three separate data sources into our Amazon S3-based data lake. Once in the data lake, we will perform ETL (or more accurately ELT) on the raw data — cleansing, augmenting, and preparing it for data analytics. Finally, we will perform aggregations on the refined data and write those final datasets back to our data lake. The data lake will be organized around the data lake pattern of bronze (aka raw), silver (aka refined), and gold (aka aggregated) data, popularized by Databricks.
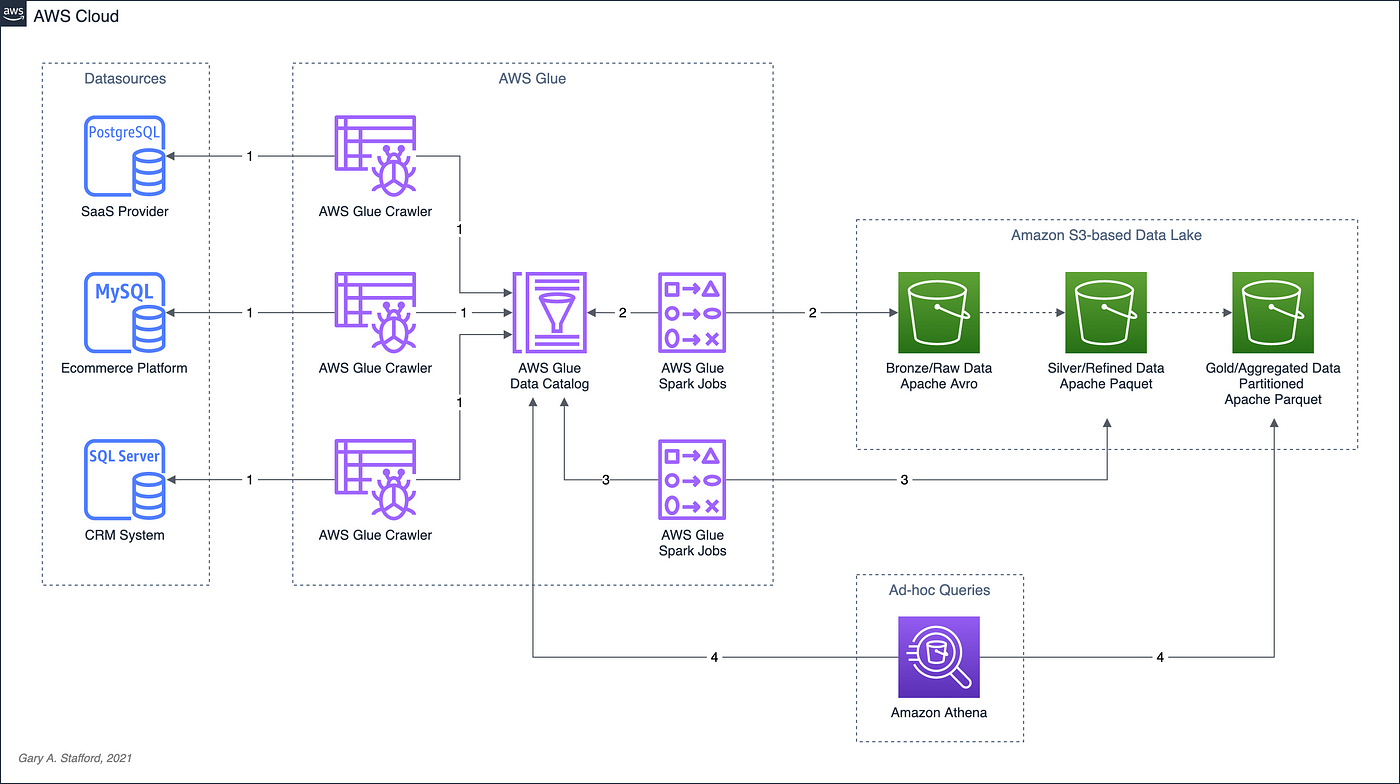
Demonstration
Source Code
The source code for this demonstration, including the SQL statements, is open-sourced and located on GitHub.
This blog represents my own viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners.
