Gary A. StaffordinArtificial Intelligence in Plain EnglishGenerative AI Videos with Stability AI’s Stable Video Diffusion XT using Asynchronous Inference on…Generating videos with Stability AI’s Stable Video Diffusion XT (SVD-XT) 1.1 foundation model on Amazon SageMaker using asynchronous…·12 min read·Apr 22, 2024----
Gary A. StaffordMultimodal Advertising Analysis and Creative Content Generation using Anthropic Claude 3 on Amazon…Explore Anthropic Claude 3 foundation models’ sophisticated vision capabilities to perform multimodal advertising analysis and develop new…·14 min read·Apr 15, 2024----
Gary A. StaffordinArtificial Intelligence in Plain EnglishCreating Short Video Animations using Amazon Bedrock, Stability AI, Photoshop, and RunwayMLLearn to create short animations from a single image using Amazon Bedrock, Stability AI’s SDXL image generation model, Adobe Photoshop, and…·9 min read·Mar 28, 2024----
Gary A. StaffordinArtificial Intelligence in Plain EnglishExplore the Power of Task-Specific Transformer Models with Amazon SageMaker and Hugging FaceExplore the efficiencies of specialized transformer models available from Hugging Face to accomplish specific NLP tasks in Amazon SageMaker…·16 min read·Mar 19, 2024----
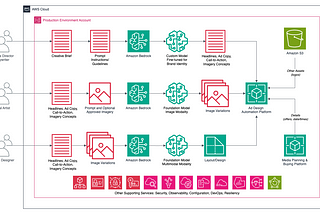
Gary A. StaffordinArtificial Intelligence in Plain EnglishCombining the Power of Generative AI with the Creative Expression of Digital Art and Design·11 min read·Jan 4, 2024----
Gary A. StaffordinArtificial Intelligence in Plain EnglishAdvanced Image Generation on NVIDIA GPU-based Amazon WorkSpaces Using A1111 Stable Diffusion Web UI…Learn how to install the Stable Diffusion Web UI from AUTOMATIC1111 and SDXL 1.0 models to Amazon WorkSpaces’ NVIDIA GPU-enabled cloud…·9 min read·Dec 11, 2023----
Gary A. StaffordinArtificial Intelligence in Plain EnglishFine-tuning Stable Diffusion XL on AWS for Generative AI-powered Product Concept DesignFine-tuning the Latest Stable Diffusion XL 1.0 Foundation Model on AWS with DreamBooth and Hugging Face’s AutoTrain·13 min read·Nov 24, 2023----
Gary A. StaffordMastering Long Document Insights: Advanced Summarization with Amazon Bedrock and Anthropic Claude 2…Unleash the Power of Generative AI for Comprehensive Document Analysis and Summarization·19 min read·Oct 28, 2023--2--2
Gary A. StaffordinAI AdvancesImage Identification and Classification with Amazon Bedrock, OpenSearch, and OpenCLIPBuild a generative AI-powered vehicle damage assessment application on AWS using Vector Engine for Amazon OpenSearch Serverless, AI21 Labs’…·20 min read·Oct 14, 2023--1--1
Gary A. StaffordinArtificial Intelligence in Plain EnglishUsing Amazon OpenSearch Serverless Vector Search and OpenAI CLIP Multimodal Model for Semantic…Learn how to use AWS’s recently announced Amazon OpenSearch Serverless Vector Search and OpenAI CLIP multimodal model to perform image…·17 min read·Sep 8, 2023----